Cómo implementar inteligencia artificial para resolver tareas de procesamiento de imágenes
Se puede enseñar a las máquinas a interpretar las imágenes de la misma manera que lo hacen nuestros cerebros y a analizar esas imágenes mucho más a fondo de lo que podemos. Cuando se aplica al procesamiento de imágenes, la inteligencia artificial (IA) puede potenciar la funcionalidad de reconocimiento y autenticación facial para garantizar la seguridad en lugares públicos, detectar y reconocer objetos y patrones en imágenes y videos, etc.
En este artículo, hablamos sobre el procesamiento de imágenes digitales y el papel de la IA en él. Describimos algunas herramientas y técnicas de procesamiento de imágenes basadas en IA que puede utilizar para desarrollar aplicaciones inteligentes. También echamos un vistazo a los modelos de red neuronal más populares utilizados para diferentes tareas de procesamiento de imágenes. Este artículo será útil para cualquiera que tenga como objetivo construir una solución de IA para el procesamiento de imágenes.
¿Qué es el procesamiento de imágenes?
En términos generales, el procesamiento de imágenes es manipular una imagen para mejorarla o extraer información de ella. Hay dos métodos de procesamiento de imágenes:
- El procesamiento de imágenes analógicas se utiliza para procesar fotografías físicas, impresiones y otras copias impresas de imágenes
- El procesamiento de imágenes digitales se utiliza para manipular imágenes digitales con la ayuda de algoritmos informáticos
En ambos casos, la entrada es una imagen. Para el procesamiento de imágenes analógicas, la salida siempre es una imagen. Sin embargo, para el procesamiento digital de imágenes, la salida puede ser una imagen o información asociada con esa imagen, como datos sobre características, características, cuadros delimitadores o máscaras.
Hoy en día, el procesamiento de imágenes es ampliamente utilizado en visualización médica, biometría, vehículos autónomos, juegos, vigilancia, aplicación de la ley y otras esferas. Estos son algunos de los principales propósitos del procesamiento de imágenes:
- Visualización – Representar los datos procesados de una manera comprensible, dando forma visual a objetos que no son visibles, por ejemplo
- Sensibilidad y restauración de imágenes – Mejorar la calidad de las imágenes procesadas
- Recuperación de imágenes – Ayuda con la búsqueda de imágenes
- Medición de objetos — Medir objetos en una imagen
- Reconocimiento de patrones: distinguir y clasificar objetos en una imagen, identificar sus posiciones y comprender la escena.
El procesamiento de imágenes digitales incluye ocho fases clave:

Veamos más de cerca cada una de estas fases.
- La adquisición de imágenes es el proceso de capturar una imagen con un sensor (como una cámara) y convertirla en una entidad manejable (por ejemplo, un arc
- El procesamiento morfológico describe las formas y estructuras de los objetos en una imagen. Las técnicas de procesamiento morfológico se pueden utilizar al crear conjuntos de datos para entrenar modelos de IA. En particular, el análisis y procesamiento morfológico se puede aplicar en la etapa de anotación, cuando describe lo que desea que su modelo de IA detecte o reconozca.

- hivo de imagen digital). Un método popular de adquisición de imágenes es el raspado.
En Apriorit, hemos creado varias herramientas personalizadas de adquisición de imágenes para ayudar a nuestros clientes a recopilar conjuntos de datos de alta calidad para entrenar modelos de redes neuronales.
- La mejora de la imagen mejora la calidad de una imagen para extraer información oculta de ella para su posterior procesamiento.
- La restauración de imágenes también mejora la calidad de una imagen, principalmente eliminando posibles corrupciónes para obtener una versión más limpia. Este proceso se basa principalmente en modelos probabilísticos y matemáticos y se puede utilizar para deshacerse del desenfoque, el ruido, los píxeles que faltan, el enfoque incorrecto de la cámara, las marcas de agua y otras corrupciones que pueden afectar negativamente el entrenamiento de una red neuronal.

- El procesamiento de imágenes en color incluye el procesamiento de imágenes en color y diferentes espacios de color. Dependiendo del tipo de imagen, podemos hablar sobre el procesamiento pseudocolor (cuando se asignan valores de escala de grises a los colores) o el procesamiento RGB (para imágenes adquiridas con un sensor a todo color).
- La compresión y descompresión de imágenes permite cambiar el tamaño y la resolución de una imagen. La compresión es responsable de reducir el tamaño y la resolución, mientras que la descompresión se utiliza para restaurar una imagen a su tamaño y resolución originales.
Estas técnicas se utilizan a menudo durante el proceso de aumento de imágenes. Cuando le faltan datos, puede ampliar su conjunto de datos con imágenes ligeramente aumentadas. De esta manera, puede mejorar la forma en que su modelo de red neuronal generaliza los datos y asegurarse de que proporcione resultados de alta calidad.

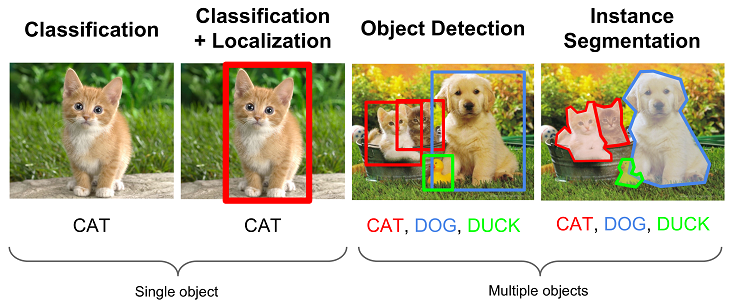
- El reconocimiento de imágenes es el proceso de identificar características específicas de objetos particulares en una imagen. El reconocimiento de imágenes con IA a menudo utiliza técnicas como la detección de objetos, el reconocimiento de objetos y la segmentación.
Aquí es donde las soluciones de IA realmente brillan. Una vez que complete todas estas fases de procesamiento de imágenes, estará listo para construir, entrenar y probar una solución de IA real. El proceso de desarrollo de aprendizaje profundo incluye un ciclo completo de operaciones desde la adquisición de datos hasta la incorporación del modelo de IA desarrollado en el sistema final.
Figura 5. Reconocimiento de imágenes con CNN
Crédito de la imagen: GitHub
- La representación y descripción es el proceso de visualizar y describir los datos procesados. Los sistemas de IA están diseñados para funcionar de la manera más eficiente posible. La salida bruta de un sistema de IA parece una matriz de números y valores que representan la información para la que se entrenó el modelo de IA. Sin embargo, en aras del rendimiento del sistema, una red neuronal profunda generalmente no incluye ninguna representación de datos de salida. Usando herramientas de visualización especiales, puede convertir estas matrices de números en imágenes legibles adecuadas para su posterior análisis.
Sin embargo, como cada una de estas fases requiere procesar cantidades masivas de datos, no puedes hacerlo manualmente. Aquí es donde los algoritmos de IA y aprendizaje automático (ML) se vuelven muy útiles.
El uso de IA y ML aumenta tanto la velocidad del procesamiento de datos como la calidad del resultado final. Por ejemplo, con la ayuda de plataformas de IA, podemos realizar con éxito tareas tan complejas como la detección de objetos, el reconocimiento facial y el reconocimiento de texto. Pero, por supuesto, para obtener resultados de alta calidad, necesitamos elegir las herramientas y métodos adecuados.
Métodos, técnicas y herramientas de procesamiento de imágenes
La mayoría de las imágenes tomadas con sensores regulares requieren preprocesamiento, ya que pueden estar mal enfocadas o contener demasiado ruido. El filtrado y la detección de bordes son dos de los métodos más comunes para procesar imágenes digitales.
- El filtrado se utiliza para mejorar y modificar la imagen de entrada. Con la ayuda de diferentes filtros, puede enfatizar o eliminar ciertas características de una imagen, reducir el ruido de la imagen, etc. Las técnicas de filtrado populares incluyen filtrado lineal, filtrado mediano y filtrado Wiener.
La detección de bordes utiliza filtros para la segmentación de imágenes y la extracción de datos. Al detectar discontinuidades en el brillo, este método ayuda a encontrar bordes significativos de objetos en imágenes procesadas. La detección de bordes Canny, la detección de bordes Sobel y la detección de bordes Roberts se encuentran entre las técnicas de detección de bordes más populares.
Figura 6. Ejemplos de detección de bordes
Crédito de la imagen: Rice University
También hay otras técnicas populares para manejar tareas de procesamiento de imágenes. La técnica de ondas es ampliamente utilizada para la compresión de imágenes, aunque también se puede utilizar para el ruido.
Algunos de estos filtros también se pueden utilizar como herramientas de aumento. Por ejemplo, en uno de nuestros proyectos recientes, desarrollamos un algoritmo de IA que utiliza la detección de bordes para descubrir los tamaños físicos de los objetos en los datos de imagen digital.
Para facilitar el uso de estas técnicas, así como la implementación de funcionalidades de procesamiento de imágenes basadas en IA en su producto, puede utilizar bibliotecas y marcos específicos. En la siguiente sección, echamos un vistazo a algunas de las bibliotecas de código abierto más populares para realizar diferentes tareas de procesamiento de imágenes con la ayuda de algoritmos de IA.
Bibliotecas de código abierto para el procesamiento de imágenes basado en IA
Las bibliotecas de visión artificial contienen funciones y algoritmos comunes de procesamiento de imágenes. Hay varias bibliotecas de código abierto que puede utilizar al desarrollar funciones de procesamiento de imágenes y visión artificial:
- OpenCV
- Biblioteca de visualización
- Anotador de imagen VGG
OpenCV
La Biblioteca de Visión por Computadora de Código Abierto (OpenCV) es una popular biblioteca de visión por computadora que proporciona cientos de algoritmos de aprendizaje por computadora y máquina y miles de funciones que componen y apoyan esos algoritmos. La biblioteca viene con interfaces C++, Java y Python y es compatible con todos los sistemas operativos móviles y de escritorio populares.
OpenCV incluye varios módulos, como un módulo de procesamiento de imágenes, un módulo de detección de objetos y un módulo de aprendizaje automático. Usando esta biblioteca, puede adquirir, comprimir, mejorar, restaurar y extraer datos de imágenes.
Biblioteca de visualización
Visualization Library es middleware C++ para aplicaciones 2D y 3D basadas en Open Graphics Library (OpenGL).Este kit de herramientas le permite crear aplicaciones portátiles y de alto rendimiento para sistemas Windows, Linux y Mac OS X. Como muchas de las clases de Visualization Library tienen un mapeo intuitivo uno a uno con funciones y características de la biblioteca OpenGL, es fácil y cómodo trabajar con este middleware.
Anotador de imagen VGG
VGG Image Annotator (VIA) es una aplicación web para la anotación de objetos. Se puede instalar directamente en un navegador web y utilizar para anotar objetos detectados en imágenes, grabaciones de audio y vídeo.
VIA es fácil de trabajar, no requiere configuración o instalación adicional y se puede usar con cualquier navegador moderno.
Marcos de aprendizaje automático y plataformas de procesamiento de imágenes
Si desea ir más allá del uso de algoritmos simples de IA, puede crear modelos personalizados de aprendizaje profundo para el procesamiento de imágenes. Para que el desarrollo sea un poco más rápido y fácil, puede utilizar plataformas y marcos especiales. A continuación, echamos un vistazo a algunos de los más populares:
- TensorFlow
- PyTorch
- Caja de herramientas de procesamiento de imágenes MATLAB
- Visión de ordenador de Microsoft
- Visión de Google Cloud
- Colaboratorio de Google (Colab)
TensorFlow
TensorFlow de Google es un popular marco de código abierto con soporte para aprendizaje automático y aprendizaje profundo. Utilizando TensorFlow, puedes crear y entrenar modelos personalizados de aprendizaje profundo. El marco también incluye un conjunto de bibliotecas, incluidas las que se pueden utilizar en proyectos de procesamiento de imágenes y aplicaciones de visión por computadora.
PyTorch
PyTorch es un marco de aprendizaje profundo de código abierto creado inicialmente por el laboratorio de investigación de IA de Facebook (FAIR). Este marco basado en Torch tiene interfaces Python, C++ y Java.
Entre otras cosas, puede usar PyTorch para crear aplicaciones de visión por computadora y procesamiento de lenguaje natural.
Caja de herramientas de procesamiento de imágenes MATLAB
MATLAB es una abreviatura de laboratorio de matriz. Es el nombre de una plataforma popular para resolver problemas científicos y matemáticos y un lenguaje de programación. Esta plataforma proporciona una Caja de Herramientas de Procesamiento de Imágenes (IPT) que incluye múltiples algoritmos y aplicaciones de flujo de trabajo para procesar, visualizar y analizar imágenes, así como para desarrollar algoritmos.
MATLAB IPT le permite automatizar los flujos de trabajo comunes de procesamiento de imágenes. Esta caja de herramientas se puede utilizar para la reducción de ruido, la mejora de imágenes, la segmentación de imágenes, el procesamiento de imágenes 3D y otras tareas. Muchas de las funciones de IPT admiten la generación de código C/C++, por lo que se pueden utilizar para implementar sistemas de visión integrados y prototipos de escritorio.
MATLAB IPT no es una plataforma de código abierto, pero tiene una prueba gratuita.
Visión de ordenador de Microsoft
Computer Vision es un servicio basado en la nube proporcionado por Microsoft que le da acceso a algoritmos avanzados para el procesamiento de imágenes y la extracción de datos. Le permite:
- analizar las características visuales y las características de una imagen
- contenido de imagen moderado
- extraer texto de las imágenes
Visión de Google Cloud
Cloud Vision es parte de la plataforma Google Cloud y ofrece un conjunto de funciones de procesamiento de imágenes. Proporciona una API para integrar características como el etiquetado y clasificación de imágenes, la localización de objetos y el reconocimiento de objetos.
Cloud Vision le permite utilizar modelos de aprendizaje automático preentrenados y crear y entrenar modelos de aprendizaje automático personalizados para resolver diferentes tareas de procesamiento de imágenes.
Colaboratorio de Google (Colab)
Google Colaboratory, también conocido como Colab, es un servicio gratuito en la nube que se puede utilizar no solo para mejorar sus habilidades de codificación, sino también para desarrollar aplicaciones de aprendizaje profundo desde cero.
Colab facilita el uso de bibliotecas populares como OpenCV, Keras y TensorFlow al desarrollar una aplicación basada en IA. El servicio se basa en Jupyter Notebooks, lo que permite a los desarrolladores de IA compartir sus conocimientos y experiencia de una manera cómoda. Además, a diferencia de servicios similares, Colab proporciona recursos GPU gratuitos.
Además de diferentes bibliotecas, marcos y plataformas, es posible que también necesite una gran base de datos de imágenes para entrenar y probar su modelo.
Hay varias bases de datos abiertas que contienen millones de imágenes etiquetadas que puede utilizar para entrenar sus aplicaciones y algoritmos de aprendizaje automático personalizados. ImageNet y Pascal VOC se encuentran entre las bases de datos gratuitas más populares para el procesamiento de imágenes.
Uso de redes neuronales para el procesamiento de imágenes
Muchas de las herramientas de las que hablamos en la sección anterior utilizan IA para resolver tareas complejas de procesamiento de imágenes. De hecho, las mejoras en la IA y el aprendizaje automático son una de las razones del impresionante progreso en la tecnología de visión por computadora que podemos ver hoy en día.
Los modelos de aprendizaje automático más efectivos para el procesamiento de imágenes utilizan redes neuronales y aprendizaje profundo. El aprendizaje profundo utiliza redes neuronales para resolver tareas complejas de manera similar a la forma en que el cerebro humano las resuelve.
Se pueden implementar diferentes tipos de redes neuronales para resolver diferentes tareas de procesamiento de imágenes, desde una simple clasificación binaria (si una imagen coincide o no con un criterio específico) hasta la segmentación de instancias. Elegir el tipo y la arquitectura correctos de una red neuronal juega un papel esencial en la creación de una solución eficiente de procesamiento de imágenes basada en IA.
A continuación, echamos un vistazo a varias redes neuronales populares y especificamos las tareas para las que son más adecuadas.
Red neuronal convolucional
Las redes neuronales convolucionales (ConvNets o CNN) son una clase de redes de aprendizaje profundo que se crearon específicamente para el procesamiento de imágenes. Sin embargo, las CNN se han aplicado con éxito a varios tipos de datos, no solo a imágenes. En estas redes, las neuronas se organizan y conectan de manera similar a cómo se organizan y conectan las neuronas en el cerebro humano. A diferencia de otras redes neuronales, las CNN requieren menos operaciones de preprocesamiento. Además, en lugar de usar filtros diseñados a mano (a pesar de poder beneficiarse de ellos), los CNN pueden aprender los filtros y características necesarios durante el entrenamiento.
Las CNN son redes neuronales multicapa que incluyen capas de entrada y salida, así como una serie de bloques de capas ocultos que consisten en:
- Capas convolucionales: responsable de filtrar la imagen de entrada y extraer características específicas como bordes, curvas y colores
- Agrupar capas – Mejorar la detección de objetos colocados inusualmente
- Capas de normalización (ReLU): mejore el rendimiento de la red normalizando las entradas de la capa anterior
- Capas completamente conectadas – Capas en las que las neuronas tienen conexiones completas con todas las activaciones en la capa anterior (similares a las redes neuronales regulares)
Todas las capas de CNN están organizadas en tres dimensiones (peso, altura y profundidad) y tienen dos componentes:
- Extracción de características
- Clasificación
En el primer componente, CNN ejecuta múltiples convoluciones y operaciones de agrupación para detectar características que luego utilizará para la clasificación de imágenes.
En el segundo componente, utilizando las características extraídas, el algoritmo de red intenta predecir cuál podría ser el objeto de la imagen con una probabilidad calculada.
Las CNN son ampliamente utilizadas para implementar IA en el procesamiento de imágenes y resolver problemas como el procesamiento de señales, la clasificación de imágenes y el reconocimiento de imágenes. Hay numerosos tipos de arquitecturas de CNN como AlexNet, ZFNet, Faster R-CNN y GoogLeNet/Inception.
La elección de la arquitectura de CNN depende de la tarea en cuestión. Por ejemplo, GoogLeNet muestra una mayor precisión para el reconocimiento de hojas que AlexNet o una CNN básica. Al mismo tiempo, debido al mayor número de capas, GoogLeNet tarda más en ejecutarse.
Máscara R-CNN
Mask R-CNN es una red neuronal profunda basada en R-CNN más rápida que se puede utilizar para separar objetos en una imagen o vídeo procesado. Esta red neuronal funciona en dos etapas:
- Segmentación: la red neuronal procesa una imagen, detecta áreas que pueden contener objetos y genera propuestas.
- Generación de cajas delimitadoras y máscaras: la red calcula una máscara binaria para cada clase y genera los resultados finales basados en estos cálculos.
Este modelo de red neuronal es flexible, ajustable y proporciona un mejor rendimiento en comparación con soluciones similares. Sin embargo, Mask R-CNN lucha con el procesamiento en tiempo real, ya que esta red neuronal es bastante pesada y las capas de máscara agregan un poco de sobrecarga de rendimiento, especialmente en comparación con Faster R-CNN.
Figura 7. Cómo funciona Mask R-CNN
Crédito de la imagen: Mask R-CNN, https://arxiv.org/abs/1703.06870
Mask R-CNN sigue siendo una de las mejores soluciones, por ejemplo, la segmentación. En Apriorit, hemos aplicado esta arquitectura de red neuronal y nuestras habilidades de procesamiento de imágenes para resolver muchas tareas complejas, incluido el procesamiento de datos de imágenes médicas y datos microscópicos médicos. También hemos desarrollado un complemento para mejorar el rendimiento de este modelo de red neuronal hasta diez veces gracias al uso de la tecnología NVIDIA TensorRT.
Red totalmente convolucional
El concepto de una red totalmente convolucional (FCN) fue ofrecido por primera vez por un equipo de investigadores de la Universidad de Berkeley. La principal diferencia entre CNN y FCN es que este último tiene una capa convolucional en lugar de una capa regular totalmente conectada. Como resultado, los FCN pueden gestionar diferentes tamaños de entrada. Además, los FCN utilizan downsampling (convolución rayada) y upsampling (convolución transpuesta) para hacer que las operaciones de convolución sean menos costosas computacionalmente.
Una red neuronal totalmente convolucional es el ajuste perfecto para las tareas de segmentación de imágenes cuando la red neuronal divide la imagen procesada en múltiples grupos de píxeles que luego se etiquetan y clasifican. Algunos de los FCN más populares utilizados para la segmentación semántica son DeepLab, RefineNet y Dilated Convolutions.
U-Net
U-Net es una red neuronal convolucional que permite una segmentación de imágenes rápida y precisa. A diferencia de otras redes neuronales de nuestra lista, U-Net fue diseñado específicamente para la segmentación de imágenes biomédicas. Por lo tanto, no es de extrañar que se crea que U-Net es superior a Mask R-CNN, especialmente en tareas tan complejas como el procesamiento médico de imágenes.
U-Net tiene una arquitectura en forma de U y tiene más canales de características en su parte de muestreo superior. Como resultado, la red propaga información de contexto a capas de mayor resolución, creando así un camino expansivo más o menos simétrico a su parte contratante.
Figura 8. La arquitectura de red neuronal U-Net
Crédito de la imagen: Universidad de Friburgo
En Apriorit, implementamos con éxito un sistema con la columna vertebral U-Net para complementar los resultados de una solución de segmentación de imágenes médicas. Este enfoque nos permitió obtener resultados de procesamiento de imágenes más diversos y nos permitió analizar los resultados recibidos con dos sistemas independientes. El análisis adicional es especialmente útil cuando un especialista en dominios no está seguro de un resultado de segmentación de imágenes en particular.
Red Generativa Adversaria
Se supone que las redes generativas adversarias (GAN) deben lidiar con uno de los mayores desafíos que enfrentan las redes neuronales en estos días: las imágenes adversarias.
Las imágenes adversariales son conocidas por causar fallas masivas en las redes neuronales. Por ejemplo, una red neuronal puede ser engañada si agrega una capa de ruido visual llamada perturbación a la imagen original. Y aunque la diferencia es casi imperceptible para el cerebro humano, los algoritmos informáticos luchan por clasificar adecuadamente las imágenes adversarias (ver Figura 9).
Figura 9. Ejemplo de clasificación errónea de imágenes adversas
Crédito de la imagen: OpenAI
Las GAN son redes dobles que incluyen dos redes, un generador y un discriminador, que se enfrentan entre sí. El generador es responsable de generar nuevos datos y se supone que el discriminador debe evaluar la autenticidad de esos datos.
Además, a diferencia de otras redes neuronales, se puede enseñar a los GAN a crear nuevos datos como imágenes, música y prosa.
Conclusión
Con la ayuda de algoritmos de aprendizaje profundo y redes neuronales, se puede enseñar a las máquinas a ver e interpretar imágenes de la manera requerida para una tarea en particular. El progreso en la implementación del procesamiento de imágenes basado en IA es impresionante y abre una amplia gama de oportunidades en campos, desde la medicina y la agricultura hasta el comercio minorista y la aplicación de la ley.
Los especialistas de inteligencia artificial de Brita Inteligencia Artificial en México tienen mucha curiosidad por la IA y el aprendizaje automático, por lo que hacemos un seguimiento de las últimas mejoras en el procesamiento de imágenes impulsado por IA y utilizamos este conocimiento cuando trabajamos en nuestros proyectos de IA.
Desarrollamos soluciones de IA y aprendizaje profundo basadas en las últimas investigaciones en procesamiento de imágenes y utilizando marcos como Keras, TensorFlow y PyTorch. Cuando el modelo final de IA está listo y un cliente está satisfecho con los resultados, lo ayudamos a integrarlo en cualquier plataforma, desde escritorio y móvil hasta web, nube e IoT.
Póngase en contacto con nosotros y con gusto lo ayudaremos a implementar la funcionalidad de procesamiento de imágenes en su aplicación web actual o a construir una solución personalizada basada en IA desde cero para cualquier plataforma.