¿Qué es el Machine Learning? : Todo lo que necesitas saber.
Esta forma generalizada y poderosa de inteligencia artificial está cambiando todas las industrias. Esto es lo que necesita saber sobre el potencial y las limitaciones del Machine Learning o el aprendizaje automático en español y cómo se está utilizando.
El Machine Learning está detrás de los chatbots y el texto predictivo, las aplicaciones de traducción de idiomas, los programas que Netflix te sugiere y cómo se presentan tus feeds de redes sociales. Alimenta vehículos autónomos y máquinas que pueden diagnosticar condiciones médicas basadas en imágenes.
Cuando las empresas hoy en día implementan programas de inteligencia artificial, lo más probable es que utilicen el Machine Learning, tanto es así que los términos a menudo se usan de manera intercambiable, y a veces ambigua. El Machine Learning es un subcampo de la inteligencia artificial que da a las computadoras la capacidad de aprender sin ser programadas explícitamente.
“En solo los últimos cinco o 10 años, el Machine Learning se ha convertido en una forma crítica, posiblemente la forma más importante, la mayoría de las partes de la IA se hacen”, dijo el profesor de MIT SloanThomas W. Malone,el director fundador del Centro de Inteligencia Colectiva del MIT. “Así que es por eso que algunas personas usan los términos IA y Machine Learning casi como sinónimos… la mayoría de los avances actuales en IA han involucrado Machine Learning”.
Con la creciente ubicuidad del aprendizaje automático, es probable que todos en los negocios lo encuentren y necesitarán algún conocimiento práctico sobre este campo. Una encuesta de Deloitte de 2020 encontró que el 67% de las empresas están usando el Machine Learning, y el 97% lo están usando o planeando usarlo el próximo año.
Desde la fabricación hasta el comercio minorista y la banca y las panaderías, incluso las empresas heredadas están utilizando el aprendizaje automático para desbloquear nuevo valor o aumentar la eficiencia. “El Machine Learning está cambiando, o cambiará, cada industria, y los líderes necesitan entender los principios básicos, el potencial y las limitaciones”, dijo el profesor de informática del MIT Aleksander Madry, director del Centro de Aprendizaje Automático Desplegable del MIT.
Aunque no todo el mundo necesita conocer los detalles técnicos, deben entender lo que hace la tecnología y lo que puede y no puede hacer, agregó Madry. “No creo que nadie pueda darse el lujo de no ser consciente de lo que está sucediendo”.
Eso incluye ser consciente de las implicaciones sociales, sociales y éticas del aprendizaje automático. “Es importante involucrar y comenzar a entender estas herramientas, y luego pensar en cómo las vas a usar bien. Tenemos que usar estas [herramientas] para el bien de todos”, dijo el Dr. Joan LaRovere, MBA ’16, médico pediátrico de cuidados intensivos cardíacos y cofundador de la organización sin fines de lucro The Virtue Foundation. “La IA tiene mucho potencial para hacer el bien, y realmente necesitamos mantener eso en nuestras lentes mientras pensamos en esto. ¿Cómo usamos esto para hacer el bien y mejor al mundo?”
¿Qué es el Machine Learning o el Aprendizaje Automático?
El Machine Learning o el Aprendizaje Automático traducido al español, es un subcampo de la inteligencia artificial, que se define ampliamente como la capacidad de una máquina para imitar el comportamiento humano inteligente. Los sistemas de inteligencia artificial se utilizan para realizar tareas complejas de una manera similar a cómo los humanos resuelven los problemas.
El objetivo de la IA es crear modelos informáticos que exhiban “comportamientos inteligentes” como los humanos, según Boris Katz, científico investigador principal y jefe del Grupo InfoLab en CSAIL. Esto significa máquinas que pueden reconocer una escena visual, entender un texto escrito en lenguaje natural o realizar una acción en el mundo físico.
El aprendizaje automático es una forma de usar la IA. Fue definido en la década de 1950 por el pionero de la IA Arthur Samuel como “el campo de estudio que da a las computadoras la capacidad de aprender sin ser programadas explícitamente”.
La definición es cierta, segúnMikey Shulman,profesor en MIT Sloan y jefe de aprendizaje automático en Kensho, que se especializa en inteligencia artificial para las comunidades financieras y de inteligencia de EE. UU. Comparó la forma tradicional de programar computadoras, o “software 1.0”, con la cocción, donde una receta requiere cantidades precisas de ingredientes y le dice al panadero que se mezcle durante una cantidad exacta de tiempo. La programación tradicional requiere de manera similar la creación de instrucciones detalladas para que la computadora la siga.
Pero en algunos casos, escribir un programa para que la máquina lo siga lleva mucho tiempo o es imposible, como entrenar a una computadora para reconocer imágenes de diferentes personas. Si bien los seres humanos pueden hacer esta tarea fácilmente, es difícil decirle a una computadora cómo hacerlo. El aprendizaje automático adopta el enfoque de permitir que las computadoras aprendan a programarse a sí mismas a través de la experiencia.
El aprendizaje automático comienza con datos: números, fotos o texto, como transacciones bancarias, imágenes de personas o incluso artículos de panadería, registros de reparación, datos de series temporales de sensores o informes de ventas. Los datos se recopilan y se preparan para ser utilizados como datos de capacitación, o la información en la que se capacitará el modelo de aprendizaje automático. Cuantos más datos, mejor será el programa.
A partir de ahí, los programadores eligen un modelo de aprendizaje automático para usar, proporcionan los datos y dejan que el modelo informático se entrene para encontrar patrones o hacer predicciones. Con el tiempo, el programador humano también puede ajustar el modelo, incluido el cambio de sus parámetros, para ayudar a empujarlo hacia resultados más precisos. (El sitio web de la científica investigadora Janelle Shane AI Weirdness es una mirada entretenida a cómo aprenden los algoritmos de aprendizaje automático y cómo pueden hacer las cosas mal, como sucedió cuando un algoritmo intentó generar recetas y creó pastel de pollo con pollo con chocolate.)
Algunos datos se mantienen fuera de los datos de entrenamiento que se utilizarán como datos de evaluación, lo que prueba cuán preciso es el modelo de aprendizaje automático cuando se muestran nuevos datos. El resultado es un modelo que se puede utilizar en el futuro con diferentes conjuntos de datos.
Los algoritmos de aprendizaje automático exitosos pueden hacer cosas diferentes, escribió Malone en un reciente informe de investigación sobre la IA y el futuro del trabajo que fue coautor de la profesora del MIT y directora de CSAIL Daniela Rus y Robert Laubacher, director asociado del Centro de Inteligencia Colectiva del MIT.
“La función de un sistema de aprendizaje automático puede ser descriptiva, lo que significa que el sistema utiliza los datos para explicar lo que sucedió; predictivo, lo que significa que el sistema utiliza los datos para predecir lo que sucederá; o prescriptivo, lo que significa que el sistema utilizará los datos para hacer sugerencias sobre qué acción tomar”, escribieron los investigadores.
Hay tres subcategorías de aprendizaje automático:
Los modelos supervisados de aprendizaje automático se entrenan con conjuntos de datos etiquetados, que permiten que los modelos aprendan y crezcan más precisos con el tiempo. Por ejemplo, un algoritmo sería entrenado con imágenes de perros y otras cosas, todas etiquetadas por humanos, y la máquina aprendería maneras de identificar imágenes de perros por sí sola. El aprendizaje automático supervisado es el tipo más común utilizado hoy en día.
En el aprendizaje automático no supervisado, un programa busca patrones en datos no etiquetados. El aprendizaje automático no supervisado puede encontrar patrones o tendencias que la gente no está buscando explícitamente. Por ejemplo, un programa de aprendizaje automático no supervisado podría mirar a través de los datos de ventas en línea e identificar diferentes tipos de clientes que realizan compras.
El aprendizaje automático de refuerzo entrena a las máquinas a través del ensayo y el error para tomar la mejor acción estableciendo un sistema de recompensas. El aprendizaje de refuerzo puede entrenar a los modelos para jugar o entrenar vehículos autónomos para conducir diciéndole a la máquina cuándo tomó las decisiones correctas, lo que le ayuda a aprender con el tiempo qué acciones debe tomar.
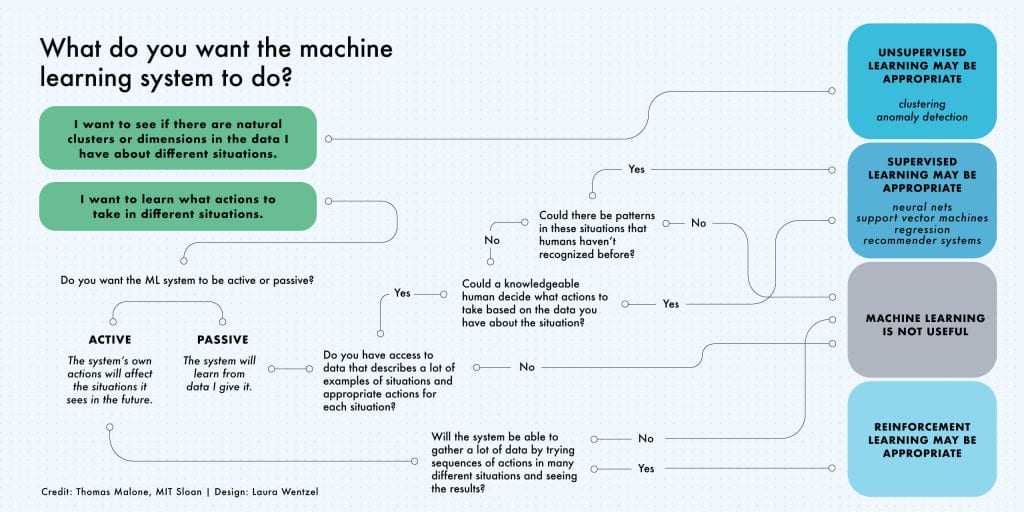
En el informe Work of the Future, Malone señaló que el aprendizaje automático es el más adecuado para situaciones con muchos datos, miles o millones de ejemplos, como grabaciones de conversaciones anteriores con clientes, registros de sensores de máquinas o transacciones en cajeros automáticos. Por ejemplo, Google Translate fue posible porque “entrenó” en la gran cantidad de información en la web, en diferentes idiomas.
En algunos casos, el aprendizaje automático puede obtener información o automatizar la toma de decisiones en casos en los que los seres humanos no podrían hacerlo, dijo Madry. “No solo puede ser más eficiente y menos costoso tener un algoritmo que haga esto, sino que a veces los humanos literalmente no son capaces de hacerlo”, dijo.
La búsqueda en Google es un ejemplo de algo que los humanos pueden hacer, pero nunca a la escala y velocidad a la que los modelos de Google son capaces de mostrar respuestas potenciales cada vez que una persona escribe una consulta, dijo Malone. “Ese no es un ejemplo de computadoras que ponen a la gente sin trabajo. Es un ejemplo de computadoras haciendo cosas que no habrían sido remotamente económicamente viables si hubieran tenido que ser hechas por humanos”.
El aprendizaje automático también está asociado con varios otros subcampos de inteligencia artificial:
Procesamiento del lenguaje natural
El procesamiento del lenguaje natural es un campo del aprendizaje automático en el que las máquinas aprenden a entender el lenguaje natural hablado y escrito por los seres humanos, en lugar de los datos y números que normalmente se utilizan para programar computadoras. Esto permite a las máquinas reconocer el idioma, entenderlo y responder a él, así como crear nuevo texto y traducir entre idiomas. El procesamiento del lenguaje natural permite tecnología familiar como chatbots y asistentes digitales como Siri o Alexa.
Redes neuronales
Las redes neuronales son una clase específica y de algoritmos de aprendizaje automático de uso común. Las redes neuronales artificiales se modelan en el cerebro humano, en el que miles o millones de nodos de procesamiento están interconectados y organizados en capas.
En una red neuronal artificial, las células o los nodos están conectados, con cada célula procesando entradas y produciendo una salida que se envía a otras neuronas. Los datos etiquetados se mueven a través de los nodos, o celdas, con cada celda realizando una función diferente. En una red neuronal entrenada para identificar si una imagen contiene un gato o no, los diferentes nodos evaluarían la información y llegarían a una salida que indica si una imagen cuenta con un gato.
Aprendizaje profundo
Las redes de aprendizaje profundo son redes neuronales con muchas capas. La red en capas puede procesar grandes cantidades de datos y determinar el “peso” de cada enlace de la red; por ejemplo, en un sistema de reconocimiento de imágenes, algunas capas de la red neuronal podrían detectar características individuales de una cara, como ojos, nariz o boca, mientras que otra capa podría saber si esas características aparecen de una manera que indique una cara.
Al igual que las redes neuronales, el aprendizaje profundo se modela en la forma en que funciona el cerebro humano y potencia muchos usos del aprendizaje automático, como vehículos autónomos, chatbots y diagnósticos médicos.
“Cuantas más capas tengas, más potencial tendrás para hacer bien las cosas complejas”, dijo Malone.
El aprendizaje profundo requiere una gran potencia informática, lo que plantea preocupaciones sobre su sostenibilidad económica y ambiental.
Cómo las empresas están utilizando el aprendizaje automático
El aprendizaje automático es el núcleo de los modelos de negocio de algunas empresas, como en el caso del algoritmo de sugerencias de Netflix o el motor de búsqueda de Google. Otras empresas se están involucrando profundamente con el aprendizaje automático, aunque no es su principal propuesta de negocio.
Otros todavía están tratando de determinar cómo usar el aprendizaje automático de una manera beneficiosa. “En mi opinión, uno de los problemas más difíciles en el aprendizaje automático es averiguar qué problemas puedo resolver con el aprendizaje automático”, dijo Shulman. “Todavía hay una brecha en el entendimiento”.
En un artículo de 2018, investigadores de la Iniciativa del MIT sobre la Economía Digital esbozaron una rúbrica de 21 preguntas para determinar si una tarea es adecuada para el aprendizaje automático. Los investigadores encontraron que ninguna ocupación no será tocada por el aprendizaje automático, pero es probable que ninguna ocupación sea completamente absorbida por él. La manera de liberar el éxito del aprendizaje automático, encontraron los investigadores, era reorganizar los trabajos en tareas discretas, algunas que se pueden hacer mediante el aprendizaje automático y otras que requieren un ser humano.
Las empresas ya están utilizando el aprendizaje automático de varias maneras, incluyendo:
Algoritmos de recomendación. Los motores de recomendación detrás de las sugerencias de Netflix y YouTube, la información que aparece en tu feed de Facebook y las recomendaciones de productos son impulsados por el aprendizaje automático. “[Los algoritmos] están tratando de aprender nuestras preferencias”, dijo Madry. “Quieren aprender, como en Twitter, qué tweets queremos que nos muestren, en Facebook, qué anuncios mostrar, qué publicaciones o contenido me gustó compartir con nosotros”.
Análisis de imágenes y detección de objetos. El aprendizaje automático puede analizar imágenes en busca de información diferente, como aprender a identificar a las personas y distinguirlas, aunque los algoritmos de reconocimiento facial son controvertidos. Los usos comerciales para esto varían. Shulman señaló que los fondos de cobertura utilizan el aprendizaje automático para analizar el número de automóviles en los estacionamientos, lo que les ayuda a aprender cómo se están desempeñando las empresas y hacer buenas apuestas.
Detección de fraude. Las máquinas pueden analizar patrones, como cómo gasta normalmente alguien o dónde compra normalmente, para identificar transacciones potencialmente fraudulentas con tarjetas de crédito, intentos de inicio de sesión o correos electrónicos de spam.
Líneas de ayuda automáticas o chatbots. Muchas empresas están implementando chatbots en línea, en los que los clientes o clientes no hablan con los seres humanos, sino que interactúan con una máquina. Estos algoritmos utilizan el aprendizaje automático y el procesamiento del lenguaje natural, con los bots aprendiendo de registros de conversaciones pasadas para llegar a respuestas apropiadas.
Coches autónomos. Gran parte de la tecnología detrás de los automóviles autónomos se basa en el aprendizaje automático, en particular el aprendizaje profundo.
Imágenes médicas y diagnóstico. Los programas de aprendizaje automático se pueden entrenar para examinar imágenes médicas u otra información y buscar ciertos marcadores de enfermedad, como una herramienta que puede predecir el riesgo de cáncer basado en una mamografía.
Cómo funciona el aprendizaje automático: promesas y desafíos
Mientras que el aprendizaje automático está alimentando la tecnología que puede ayudar a los trabajadores o abrir nuevas posibilidades para las empresas, hay varias cosas que los líderes empresariales deben saber sobre el aprendizaje automático y sus límites.
Explicabilidad
Un área de preocupación es lo que algunos expertos llaman explicabilidad, o la capacidad de tener claro lo que están haciendo los modelos de aprendizaje automático y cómo toman decisiones. “Entender por qué un modelo hace lo que hace es en realidad una pregunta muy difícil, y siempre tienes que preguntarte eso”, dijo Madry. “Nunca debes tratar esto como una caja negra, que solo viene como un oráculo… sí, deberías usarlo, pero luego tratar de tener una idea de cuáles son las reglas generales que se le ocurrieron? Y luego validarlos”.
Esto es especialmente importante porque los sistemas pueden ser engañados y socavados, o simplemente fracasar en ciertas tareas, incluso aquellos humanos pueden funcionar fácilmente. Por ejemplo, ajustar los metadatos en las imágenes puede confundir a las computadoras; con unos pocos ajustes, una máquina identifica una imagen de un perro como un avestruz.
Madry señaló otro ejemplo en el que un algoritmo de aprendizaje automático que examina los rayos X parecía superar a los médicos. Pero resultó que el algoritmo correlacionaba los resultados con las máquinas que tomaron la imagen, no necesariamente la imagen en sí. La tuberculosis es más común en los países en desarrollo, que tienden a tener máquinas más antiguas. El programa de aprendizaje automático aprendió que si la radiografía se tomaba en una máquina más antigua, el paciente tenía más probabilidades de tener tuberculosis. Completó la tarea, pero no de la manera que los programadores pretendían o encontrarían útil.
La importancia de explicar cómo funciona un modelo, y su precisión, puede variar dependiendo de cómo se esté utilizando, dijo Shulman. Si bien la mayoría de los problemas bien planteados se pueden resolver a través del aprendizaje automático, dijo, la gente debe asumir en este momento que los modelos solo funcionan con alrededor del 95% de la precisión humana. Podría estar bien con el programador y el espectador si un algoritmo que recomienda películas es 95% preciso, pero ese nivel de precisión no sería suficiente para un vehículo autónomo o un programa diseñado para encontrar fallas graves en la maquinaria.
Sesgo y resultados no deseados
Las máquinas son entrenadas por humanos, y los sesgos humanos se pueden incorporar en algoritmos; si la información sesgada, o los datos que reflejan las desigualdades existentes, se alimentan de un programa de aprendizaje automático, el programa aprenderá a replicarlo y perpetuar formas de discriminación. Los chatbots entrenados sobre cómo la gente conversa en Twitter pueden aprender un lenguaje ofensivo y racista, por ejemplo.
En algunos casos, los modelos de aprendizaje automático crean o exacerban problemas sociales. Por ejemplo, Facebook ha utilizado el aprendizaje automático como una herramienta para mostrar a los usuarios anuncios y contenido que los interesará e interactuará, lo que ha llevado a modelos que muestran a la gente contenido extremo que conduce a la polarización y a la propagación de teorías de conspiración cuando se muestra a las personas contenido incendiario, partidista o inexacto.
Formas de luchar contra los sesgos en el aprendizaje automático, incluida la investigación exhaustiva de los datos de capacitación y el apoyo organizativo detrás de los esfuerzos éticosde inteligencia artificial, como asegurarse de que su organización adopte la IA centrada en el ser humano, la práctica de buscar información de personas de diferentes orígenes, experiencias y estilos de vida al diseñar sistemas de inteligencia artificial. Las iniciativas que trabajan en este tema incluyen la Liga de Justicia Algorítmica y el proyecto La Máquina Moral.
Poner el aprendizaje automático a trabajar
Shulman dijo que los ejecutivos tienden a luchar con la comprensión de dónde el aprendizaje automático puede realmente agregar valor a su empresa. Lo que es engañoso para una empresa es fundamental para otra, y las empresas deben evitar las tendencias y encontrar casos de uso comercial que funcionen para ellas.
El aprendizaje automático está cambiando, o cambiará, cada industria, y los líderes necesitan entender los principios básicos, el potencial y las limitaciones.Aleksander MadryProfesor de Ciencias de la Computación del MIT
La forma en que funciona el aprendizaje automático para Amazon probablemente no se traducirá en una compañía de automóviles, dijo Shulman, mientras que Amazon ha encontrado éxito con asistentes de voz y altavoces operados por voz, eso no significa que las compañías de automóviles deban priorizar la adición de altavoces a los automóviles. Lo más probable, dijo, es que la compañía de automóviles encuentre una manera de usar el aprendizaje automático en la línea de fábrica que ahorre o gane mucho dinero.
“El campo se está moviendo tan rápido, y eso es increíble, pero hace que sea difícil para los ejecutivos tomar decisiones al respecto y decidir cuántos recursos invertir en él”, dijo Shulman.
También es mejor evitar ver el aprendizaje automático como una solución en busca de un problema, dijo Shulman. Algunas empresas podrían terminar tratando de adaptar el aprendizaje automático a un uso comercial. En lugar de comenzar con un enfoque en la tecnología, las empresas deben comenzar con un enfoque en un problema empresarial o una necesidad del cliente que podría satisfacerse con el aprendizaje automático.
Una comprensión básica del aprendizaje automático es importante, dijo LaRovere, pero encontrar el uso correcto del aprendizaje automático en última instancia depende de que las personas con diferentes experiencia trabajen juntas. “No soy un científico de datos. No estoy haciendo el trabajo real de ingeniería de datos, toda la adquisición, procesamiento y forcejeo de datos para habilitar las aplicaciones de aprendizaje automático, pero lo entiendo lo suficientemente bien como para poder trabajar con esos equipos para obtener las respuestas que necesitamos y tener el impacto que necesitamos”, dijo. “Realmente tienes que trabajar en equipo”.