¿Qué es el deep learning o aprendizaje profundo?
El deep learning o el aprendizaje profundo es un subcampo del aprendizaje automático que se ocupa de algoritmos inspirados en la estructura y función del cerebro llamados redes neuronales artificiales.
Si recién estás empezando en el campo del aprendizaje profundo o tuviste algo de experiencia con redes neuronales hace algún tiempo, puedes estar confundido. Sé que al principio estaba confundido, al igual que muchos de mis colegas y amigos que aprendieron y usaron redes neuronales en la década de 1990 y principios de la década de 2000.
Los líderes y expertos en el campo tienen ideas de lo que es el aprendizaje profundo y estas perspectivas específicas y matizadas arrojan mucha luz sobre de qué se trata el aprendizaje profundo.
En este post, descubrirás exactamente qué es el aprendizaje profundo escuchando a una variedad de expertos y líderes en el campo.
Comience su proyecto con mi nuevo libro Deep Learning With Python, que incluye tutoriales paso a paso y los archivos de código fuente de Python para todos los ejemplos.
Sumergámonos.
¿Qué es el aprendizaje profundo?
El aprendizaje profundo son grandes redes neuronales
Andrew Ng de Coursera y científico jefe de Baidu Research fundaron formalmente Google Brain que finalmente resultó en la producción de tecnologías de aprendizaje profundo en un gran número de servicios de Google.
Ha hablado y escrito mucho sobre lo que es el aprendizaje profundo y es un buen lugar para comenzar.
En las primeras charlas sobre aprendizaje profundo, Andrew describió el aprendizaje profundo en el contexto de las redes neuronales artificiales tradicionales. En la charla de 2013 titulada “Aprendizaje profundo, aprendizaje autodidacta y aprendizaje de características no supervisado”, describió la idea del aprendizaje profundo como:
Usando simulaciones cerebrales, esperamos:
– Hacer que los algoritmos de aprendizaje sean mucho mejores y fáciles de usar.
– Hacer avances revolucionarios en el aprendizaje automático y la IA.
Creo que esta es nuestra mejor oportunidad de avanzar hacia la IA real
Más tarde, sus comentarios se volvieron más matizados.
El núcleo del aprendizaje profundo según Andrew es que ahora tenemos computadoras lo suficientemente rápidas y suficientes datos para entrenar realmente grandes redes neuronales. Al discutir por qué ahora es el momento en que el aprendizaje profundo está despegando en ExtractConf 2015 en una charla titulada “Lo que los científicos de datos deben saber sobre el aprendizaje profundo”, comentó:
redes neuronales muy grandes que ahora podemos tener y… enormes cantidades de datos a los que tenemos acceso
También comentó sobre el importante punto de que todo se trata de escala. Que a medida que construimos redes neuronales más grandes y las entrenamos con más y más datos, su rendimiento continúa aumentando. Esto es generalmente diferente a otras técnicas de aprendizaje automático que alcanzan una meseta en rendimiento.
para la mayoría de los sabores de las viejas generaciones de algoritmos de aprendizaje… el rendimiento se estabilizará. … el aprendizaje profundo … es la primera clase de algoritmos … que es escalable. … el rendimiento sigue mejorando a medida que les alimentas más datos
Proporciona una bonita caricatura de esto en sus diapositivas: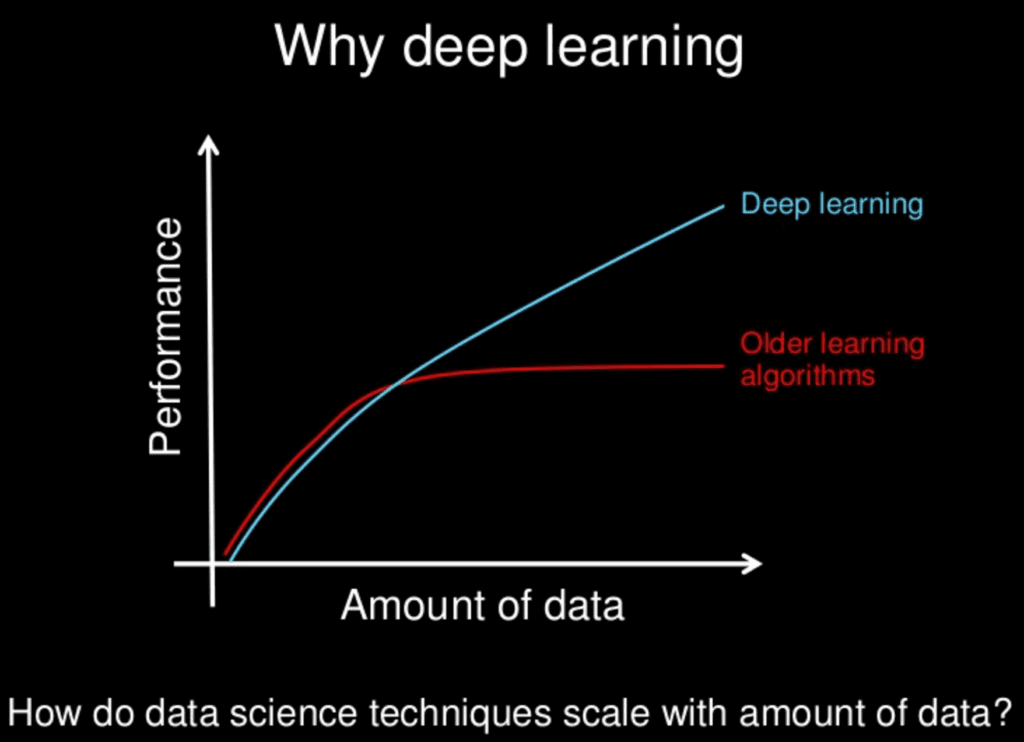
¿Por qué Deep Learning?
Slide por Andrew Ng
Por último, es claro señalar que los beneficios del aprendizaje profundo que estamos viendo en la práctica provienen del aprendizaje supervisado. De la charla ExtractConf de 2015, comentó:
casi todo el valor actual del aprendizaje profundo es a través del aprendizaje supervisado o el aprendizaje a partir de datos etiquetados
Anteriormente, en una charla con la Universidad de Stanford titulada “Aprendizaje profundo” en 2014, hizo un comentario similar:
una razón por la que el aprendizaje profundo ha despegado como loco es porque es fantástico en el aprendizaje supervisado
Andrew a menudo menciona que deberíamos y veremos más beneficios provenientes del lado no supervisado de las pistas a medida que el campo madure para lidiar con la abundancia de datos no etiquetados disponibles.
Jeff Dean es asistente y becario senior de Google en el Grupo de Sistemas e Infraestructura de Google y ha estado involucrado y tal vez parcialmente responsable de la escala y adopción del aprendizaje profundo dentro de Google. Jeff participó en el proyecto Google Brain y en el desarrollo del software de aprendizaje profundo a gran escala DistBelief y más tarde TensorFlow.
En una charla de 2016 titulada “Aprendizaje profundo para construir sistemas informáticos inteligentes”, hizo un comentario en la línea similar, que el aprendizaje profundo realmente se trata de grandes redes neuronales.
Cuando escuches el término aprendizaje profundo, solo piensa en una gran red neuronal profunda. Deep se refiere al número de capas típicamente y, por lo tanto, este tipo de término popular que se ha adoptado en la prensa. Creo que en ellos son redes neuronales profundas en general.
Ha dado esta charla varias veces, y en un conjunto modificado de diapositivas para la misma charla, destaca la escalabilidad de las redes neuronales, lo que indica que los resultados mejoran con más datos y modelos más grandes, que a su vez requieren más computación para entrenar.
Los resultados mejoran con más datos, modelos más grandes, más computación
Slide by Jeff Dean, Todos los derechos reservados.
El aprendizaje profundo es un aprendizaje jerárquico de características
Además de la escalabilidad, otro beneficio a menudo citado de los modelos de aprendizaje profundo es su capacidad para realizar la extracción automática de características a partir de datos brutos, también llamado aprendizaje de características.
Yoshua Bengio es otro líder en aprendizaje profundo, aunque comenzó con un gran interés en el aprendizaje automático de características que las grandes redes neuronales son capaces de lograr.
Describe el aprendizaje profundo en términos de la capacidad de los algoritmos para descubrir y aprender buenas representaciones utilizando el aprendizaje de características. En su artículo de 2012 titulado “Aprendizaje profundo de representaciones para el aprendizaje no supervisado y de transferencia”, comentó:
Los algoritmos de aprendizaje profundo buscan explotar la estructura desconocida en la distribución de entrada para descubrir buenas representaciones, a menudo en múltiples niveles, con características aprendidas de nivel superior definidas en términos de características de nivel inferior
Una perspectiva elaborada del aprendizaje profundo en este sentido se proporciona en su informe técnico de 2009 titulado “Aprender arquitecturas profundas para la IA“, donde enfatiza la importancia de la jerarquía en el aprendizaje de características.
Los métodos de aprendizaje profundo tienen como objetivo aprender jerarquías de características con características de niveles superiores de la jerarquía formada por la composición de características de nivel inferior. Aprender automáticamente las características en múltiples niveles de abstracción permite a un sistema aprender funciones complejas que mapean la entrada a la salida directamente a partir de los datos, sin depender completamente de las características hechas por el hombre.
En el libro que pronto se publicará titulado “Aprendizaje profundo“, en coautoría con Ian Goodfellow y Aaron Courville, definen el aprendizaje profundo en términos de la profundidad de la arquitectura de los modelos.
La jerarquía de conceptos permite a la computadora aprender conceptos complicados construyéndolos a partir de otros más simples. Si dibujamos un gráfico que muestre cómo se construyen estos conceptos uno encima del otro, el gráfico es profundo, con muchas capas. Por esta razón, llamamos a este enfoque al aprendizaje profundo de la IA.
Este es un libro importante y es probable que se convierta en el recurso definitivo para el campo durante algún tiempo. El libro continúa describiendo los perceptrones multicapa como un algoritmo utilizado en el campo del aprendizaje profundo, dando la idea de que el aprendizaje profundo ha subsumido las redes neuronales artificiales.
El ejemplo por excelencia de un modelo de aprendizaje profundo es la red profunda feedforward o perceptrón multicapa (MLP).
Peter Norvig es el Director de Investigación de Google y famoso por su libro de texto sobre IA titulado “Inteligencia Artificial: Un Enfoque Moderno“.
En una charla de 2016 que dio titulada “Aprendizaje profundo y comprensión versus Ingeniería y verificación de software”, definió el aprendizaje profundo de una manera muy similar a Yoshua, centrándose en el poder de abstracción permitido por el uso de una estructura de red más profunda.
una especie de aprendizaje donde la representación que formas tiene varios niveles de abstracción, en lugar de una entrada directa a la salida
¿Por qué llamarlo “Aprendizaje profundo“?
¿Por qué no solo “Redes neuronales artificiales“?
Geoffrey Hinton es pionero en el campo de las redes neuronales artificiales y coeditó el primer artículo sobre el algoritmo de retropropagación para entrenar redes de perceptrón multicapa.
Puede que haya comenzado la introducción del fraseo “profundo” para describir el desarrollo de grandes redes neuronales artificiales.
Fue coautor de un artículo en 2006 titulado “Un algoritmo de aprendizaje rápido para redes de creencias profundas” en el que describen un enfoque para entrenar “profundo” (como en una red de muchas capas) de máquinas Boltzmann restringidas.
Usando priores complementarios, derivamos un algoritmo rápido y codicioso que puede aprender redes de creencias profundas y dirigidas una capa a la vez, siempre que las dos capas superiores formen una memoria asociativa no dirigida.
Este artículo y el documento relacionado del que Geoff fue coautor titulado “Máquinas profundas de Boltzmann” en una red profunda no dirigida fueron bien recibidos por la comunidad (ahora citados muchos cientos de veces) porque fueron ejemplos exitosos de entrenamiento codicioso de redes en capas, lo que permitió muchas más capas en redes de avance.
En un artículo de coautoría en Science titulado “Reducción de la dimensionalidad de los datos con redes neuronales“, se quedaron con la misma descripción de “profundo” para describir su enfoque para desarrollar redes con muchas más capas de las típicas anteriormente.
Describimos una forma efectiva de inicializar los pesos que permite a las redes de codificador automático profundo aprender códigos de baja dimensión que funcionan mucho mejor que el análisis de componentes principales como una herramienta para reducir la dimensionalidad de los datos.
En el mismo artículo, hacen un comentario interesante que encaja con el comentario de Andrew Ng sobre el reciente aumento de la potencia informática y el acceso a grandes conjuntos de datos que ha desatado la capacidad sin explotar de las redes neuronales cuando se usan a mayor escala.
Ha sido obvio desde la década de 1980 que la retropropagación a través de codificadores automáticos profundos sería muy efectiva para la reducción de la dimensionalidad no lineal, siempre que las computadoras fueran lo suficientemente rápidas, los conjuntos de datos fueran lo suficientemente grandes y los pesos iniciales estuvieran lo suficientemente cerca de una buena solución. Las tres condiciones ya están cumplidas.
En una charla con la Royal Society en 2016 titulada “Aprendizaje profundo”, Geoff comentó que las redes de creencias profundas fueron el comienzo del aprendizaje profundo en 2006 y que la primera aplicación exitosa de esta nueva ola de aprendizaje profundo fue al reconocimiento del habla en 2009 titulada “Modelado acústico usando redes de creencias profundas”, logrando resultados de última generación.
Fueron los resultados los que hicieron que el reconocimiento del habla y las comunidades de redes neuronales tomaran nota, el uso “profundo” como diferenciador en técnicas anteriores de redes neuronales lo que probablemente resultó en el cambio de nombre.
Las descripciones del aprendizaje profundo en la charla de la Royal Society están muy centradas en la retropropagación como cabría esperar. Interesante, da 4 razones por las que la retropropagación (léase “aprendizaje profundo”) no despegó la última vez en la década de 1990. Los dos primeros puntos coinciden con los comentarios de Andrew Ng anteriores sobre los conjuntos de datos demasiado pequeños y los ordenadores demasiado lentos.
¿Qué estaba mal con la retropropagación en 1986?
Slide by Geoff Hinton, todos los derechos reservados.
El aprendizaje profundo como aprendizaje escalable en todos los dominios
El aprendizaje profundo sobresale en dominios problemáticos donde las entradas (e incluso la salida) son analógicas. Es decir, no son unas pocas cantidades en formato tabular, sino imágenes de datos de píxeles, documentos de datos de texto o archivos de datos de audio.
Yann LeCun es el director de Facebook Research y es el padre de la arquitectura de red que sobresale en el reconocimiento de objetos en datos de imagen llamada Red Neuronal Convolucional (CNN). Esta técnica está teniendo un gran éxito porque, al igual que las redes neuronales multicapa de avance de perceptrón, la técnica se escala con datos y tamaño del modelo y se puede entrenar con retropropagación.
Esto sesga su definición de aprendizaje profundo como el desarrollo de CNN muy grandes, que han tenido un gran éxito en el reconocimiento de objetos en fotografías.
En una charla de 2016 en el Laboratorio Nacional Lawrence Livermore titulada “Acelerar la comprensión: aprendizaje profundo, aplicaciones inteligentes y GPU”, describió el aprendizaje profundo en general como representaciones jerárquicas de aprendizaje y lo define como un enfoque escalable para construir sistemas de reconocimiento de objetos:
el aprendizaje profundo [es] … una tubería de módulos, todos los cuales son entrenables. … profundo porque [tiene] múltiples etapas en el proceso de reconocer un objeto y todas esas etapas son parte del entrenamiento”
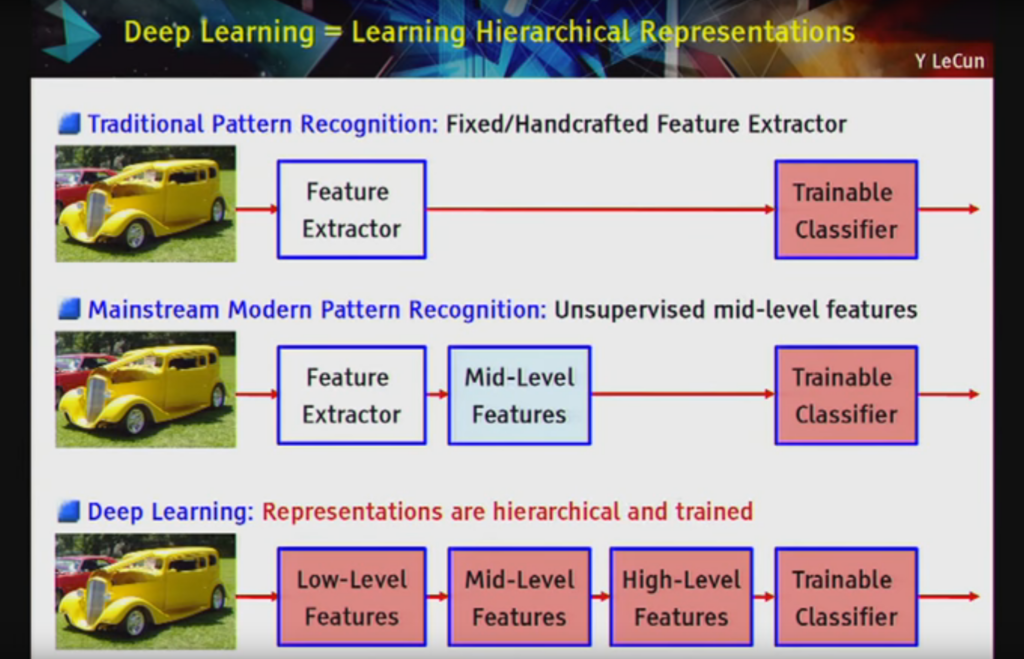
Aprendizaje profundo = Aprendizaje de representaciones jerárquicas
Slide by Yann LeCun, todos los derechos reservados.
Jurgen Schmidhuber es el padre de otro algoritmo popular que, como MLP y CNN, también escala con tamaño de modelo y tamaño de conjunto de datos y se puede entrenar con retropropagación, pero en su lugar se adapta a los datos de secuencia de aprendizaje, llamada Long Short-Term Memory Network (LSTM), un tipo de red neuronal recurrente.
Vemos cierta confusión en la redacción del campo como “aprendizaje profundo”. En su artículo de 2014 titulado “Aprendizaje profundo en redes neuronales: una visión general”, comenta el nombramiento problemático del campo y la diferenciación del aprendizaje profundo del aprendizaje superficial. También describe de manera interesante la profundidad en términos de la complejidad del problema en lugar del modelo utilizado para resolver el problema.
¿A qué profundidad del problema termina el aprendizaje superficial y comienza el aprendizaje profundo? Las discusiones con expertos en DL aún no han dado una respuesta concluyente a esta pregunta. […], permítanme definir a los efectos de esta visión general: los problemas de profundidad > 10 requieren un aprendizaje muy profundo.
Demis Hassabis es el fundador de DeepMind, más tarde adquirido por Google. DeepMind hizo el gran avance de combinar técnicas de aprendizaje profundo con aprendizaje de refuerzo para manejar problemas de aprendizaje complejos como el juego, famoso demostrado al jugar juegos de Atari y el juego Go with Alpha Go.
De acuerdo con el nombre, llamaron a su nueva técnica una Red Q Profunda, combinando Aprendizaje Profundo con Aprendizaje Q. También llaman al campo de estudio más amplio “Aprendizaje de Refuerzo Profundo”.
En su documento de naturaleza de 2015 titulado “Control a nivel humano a través del aprendizaje de refuerzo profundo“, comentan el importante papel de las redes neuronales profundas en su avance y destacan la necesidad de abstracción jerárquica.
Para lograr esto, desarrollamos un agente novedoso, una red Q profunda (DQN), que es capaz de combinar el aprendizaje de refuerzo con una clase de red neuronal artificial conocida como redes neuronales profundas. En particular, los avances recientes en las redes neuronales profundas, en las que se utilizan varias capas de nodos para construir representaciones progresivamente más abstractas de los datos, han hecho posible que las redes neuronales artificiales aprendan conceptos como categorías de objetos directamente de datos sensoriales crudos.
Finalmente, en lo que puede considerarse un documento definitorio en el campo, Yann LeCun, Yoshua Bengio y Geoffrey Hinton publicaron un artículo en Nature titulado simplemente “Aprendizaje profundo“. En él, se abren con una definición limpia de aprendizaje profundo destacando el enfoque multicapa.
El aprendizaje profundo permite que los modelos computacionales que se componen de múltiples capas de procesamiento aprendan representaciones de datos con múltiples niveles de abstracción.
Más tarde, el enfoque multicapa se describe en términos de aprendizaje de representación y abstracción.
Los métodos de aprendizaje profundo son métodos de aprendizaje de representación con múltiples niveles de representación, obtenidos componiendo módulos simples pero no lineales que transforman cada uno la representación en un nivel (comenzando con la entrada bruta) en una representación a un nivel más alto y ligeramente más abstracto. […] El aspecto clave del aprendizaje profundo es que estas capas de características no están diseñadas por ingenieros humanos: se aprenden de los datos utilizando un procedimiento de aprendizaje de propósito general.
Esta es una descripción agradable y genérica, y podría describir fácilmente la mayoría de los algoritmos de redes neuronales artificiales. También es una buena nota para terminar.
Resumen
En este post descubriste que el aprendizaje profundo son solo redes neuronales muy grandes en muchos más datos, lo que requiere computadoras más grandes.
Aunque los primeros enfoques publicados por Hinton y colaboradores se centran en el entrenamiento codicioso en capas y en métodos no supervisados como los codificadores automáticos, el aprendizaje profundo moderno de última generación se centra en entrenar modelos de redes neuronales profundas (muchas capas) utilizando el algoritmo de retropropagación. Las técnicas más populares son:
- Redes de perceptrones multicapa.
- Redes neuronales convolucionales.
- Redes neuronales recurrentes de memoria a corto plazo.
Espero que esto haya aclarado qué es el aprendizaje profundo y cómo encajan las definiciones principales bajo el único paraguas.
Brita Inteligencia Artificial México – Empresa de Inteligencia Artificial, Machine Learning y Deep Learning en México
Empresa de Inteligencia Artificial en México